26 Jan 2022
Azure Databricks - Insight

This insight introduces the set of fundamental concepts you need to understand in order to use Azure Databricks Workspace effectively.
Azure Databricks is a data analytics platform optimized for the Microsoft Azure cloud services platform. Azure Databricks offers three environments for developing data-intensive applications: Databricks SQL, Databricks Data Science & Engineering, and Databricks Machine Learning.
Databricks SQL provides an easy-to-use platform for analysts who want to run SQL queries on their data lake, create multiple visualization types to explore query results from different perspectives, and build and share dashboards.
Databricks Data Science & Engineering provides an interactive workspace that enables collaboration between data engineers, data scientists, and machine learning engineers. For a big data pipeline, the data (raw or structured) is ingested into Azure through Azure Data Factory in batches or streamed near real-time using Apache Kafka, Event Hub, or IoT Hub. This data lands in a data lake for long term persisted storage, in Azure Blob Storage or Azure Data Lake Storage. As part of your analytics workflow, use Azure Databricks to read data from multiple data sources and turn it into breakthrough insights using Spark.
Databricks Machine Learning is an integrated end-to-end machine learning environment incorporating managed services for experiment tracking, model training, feature development and management, and feature and model serving.
Workspace
A workspace is an environment for accessing all of your Azure Databricks assets. A workspace organizes objects (notebooks, libraries, dashboards, and experiments) into folders and provides access to data objects and computational resources.
This section describes the objects contained in the Azure Databricks workspace folders.
A web-based interface to documents that contain runnable commands, visualizations, and narrative text.
An interface that provides organized access to visualizations.
A package of code is available to the notebook or job running on your cluster. Databricks runtimes include many libraries and you can add your own.
A folder whose contents are co-versioned together by syncing them to a remote Git repository.
A collection of MLflow runs for training a machine learning model.
Interface
This section describes the interfaces that Azure Databricks supports for accessing your assets: UI, API, and command-line (CLI).
UI
The Azure Databricks UI provides an easy-to-use graphical interface to workspace folders and their contained objects, data objects, and computational resources.
There are three versions of the REST API: 2.1, 2.0, and 1.2. The REST APIs 2.1 and 2.0 support most of the functionality of the REST API 1.2 and additional functionality and are preferred.
An open-source project hosted on GitHub. The CLI is built on top of the REST API (latest).
Data management
This section describes the objects that hold the data on which you perform analytics and feed into machine learning algorithms.
A filesystem abstraction layer over a blob store. It contains directories, which can contain files (data files, libraries, and images), and other directories. DBFS is automatically populated with some datasets that you can use to learn Azure Databricks.
A collection of information that is organized so that it can be easily accessed, managed, and updated.
A representation of structured data. You query tables with Apache Spark SQL and Apache Spark APIs.
The component that stores all the structure information of the various tables and partitions in the data warehouse including column and column type information, the serializers and deserializers necessary to read and write data, and the corresponding files where the data is stored. Every Azure Databricks deployment has a central Hive metastore accessible by all clusters to persist table metadata. You also have the option to use an existing external Hive metastore.
Computation Management
This section describes concepts that you need to know to run computations in Azure Databricks.
A set of computation resources and configurations on which you run notebooks and jobs. There are two types of clusters: all-purpose and job.
- You create an all-purpose cluster using the UI, CLI, or REST API. You can manually terminate and restart an all-purpose cluster. Multiple users can share such clusters to do collaborative interactive analysis.
- The Azure Databricks job scheduler creates a job cluster when you run a job on a new job cluster and terminates the cluster when the job is complete. You cannot restart an job cluster.
A set of idle, ready-to-use instances that reduce cluster start and auto-scaling times. When attached to a pool, a cluster allocates its driver and worker nodes from the pool. If the pool does not have sufficient idle resources to accommodate the cluster’s request, the pool expands by allocating new instances from the instance provider. When an attached cluster is terminated, the instances it used are returned to the pool and can be reused by a different cluster.
The set of core components that run on the clusters managed by Azure Databricks. Azure Databricks offers several types of runtimes:
- Databricks Runtime includes Apache Spark but also adds a number of components and updates that substantially improve the usability, performance, and security of big data analytics.
- Databricks Runtime for Machine Learning is built on Databricks Runtime and provides a ready-to-go environment for machine learning and data science. It contains multiple popular libraries, including TensorFlow, Keras, PyTorch, and XGBoost.
- Databricks Runtime for Genomics is a version of Databricks Runtime optimized for working with genomic and biomedical data.
- Databricks Light is the Azure Databricks packaging of the open source Apache Spark runtime. It provides a runtime option for jobs that don’t need the advanced performance, reliability, or autoscaling benefits provided by Databricks Runtime. You can select Databricks Light only when you create a cluster to run a JAR, Python, or spark-submit job; you cannot select this runtime for clusters on which you run interactive or notebook job workloads.
A non-interactive mechanism for running a notebook or library either immediately or on a scheduled basis.
Workload
Azure Databricks identifies two types of workloads subject to different pricing schemes: data engineering (job) and data analytics (all-purpose).
- Data engineering An (automated) workload runs on a job cluster which the Azure Databricks job scheduler creates for each workload.
- Data analytics An (interactive) workload runs on an all-purpose cluster. Interactive workloads typically run commands within an Azure Databricks notebook. However, running a job on an existing all-purpose cluster is also treated as an interactive workload.
Execution context
The state for a REPL environment for each supported programming language. The languages supported are Python, R, Scala, and SQL.
Machine learning
This section describes concepts related to machine learning in Azure Databricks.
The main unit of organization for tracking machine learning model development. Experiments organize, display, and control access to individual logged runs of model training code.
A centralized repository of features. Databricks Feature Store enables feature sharing and discovery across your organization and also ensures that the same feature computation code is used for model training and inference.
A trained machine learning or deep learning model that has been registered in Model Registry.
Authentication and authorization
This section describes concepts that you need to know when you manage Azure Databricks users and their access to Azure Databricks assets.
User
A unique individual who has access to the system.
Group
A collection of users.
Access control list (ACL)
A list of permissions attached to the workspace, cluster, job, table, or experiment. An ACL specifies which users or system processes are granted access to the objects, as well as what operations are allowed on the assets. Each entry in a typical ACL specifies a subject and an operation.
Azure Databricks Architecture
The Databricks Unified Data Analytics Platform, from the original creators of Apache Spark, enables data teams to collaborate in order to solve some of the world’s toughest problems.
High-level architecture
Azure Databricks is structured to enable secure cross-functional team collaboration while keeping a significant amount of backend services managed by Azure Databricks so you can stay focused on your data science, data analytics, and data engineering tasks.
Azure Databricks operates out of a control plane and a data plane.
- The control plane includes the backend services that Azure Databricks manages in its own Azure account. Notebook commands and many other workspace configurations are stored in the control plane and encrypted at rest.
- The data plane is managed by your Azure account and is where your data resides. This is also where data is processed. You can use Azure Databricks connectors so that your clusters can connect to external data sources outside of your Azure account to ingest data or for storage. You can also ingest data from external streaming data sources, such as events data, streaming data, IoT data, and more.
Although architectures can vary depending on custom configurations (such as when you’ve deployed a Azure Databricks workspace to your own virtual network, also known as VNet injection), the following architecture diagram represents the most common structure and flow of data for Azure Databricks.
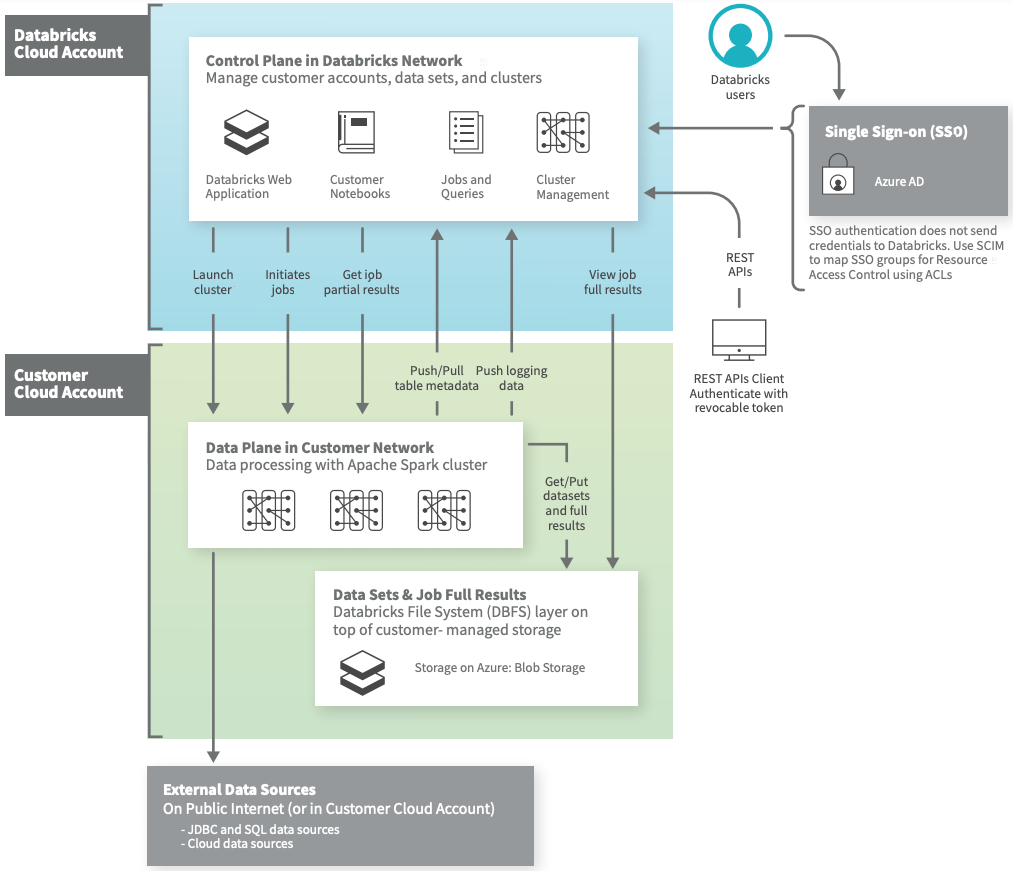
For more architecture information, see Manage virtual networks.
Your data is stored at rest in your Azure account in the data plane and in your own data sources, not the control plane, so you maintain control and ownership of your data.
Job results reside in storage in your account.
Interactive notebook results are stored in a combination of the control plane (partial results for presentation in the UI) and your Azure storage. If you want interactive notebook results stored only in your cloud account storage, you can ask your Databricks representative to enable interactive notebook results in the customer account for your workspace. Note that some metadata about results, such as chart column names, continues to be stored in the control plane. This feature is in Public Preview.


